Abstract
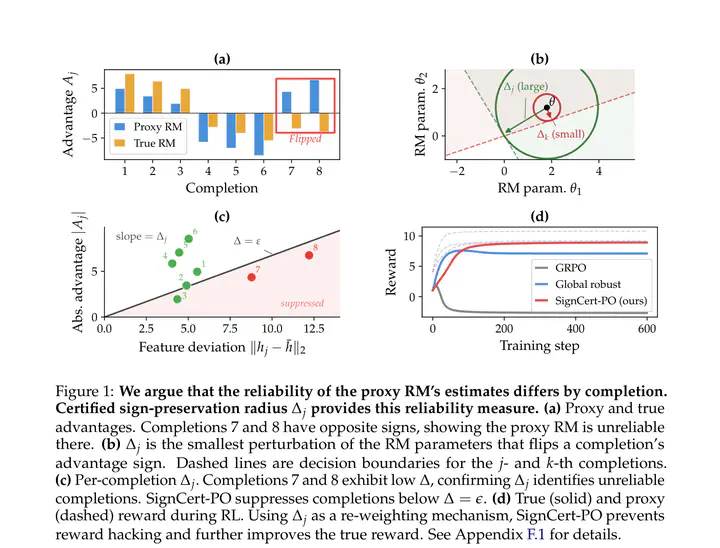
Reward models (RMs) used in reinforcement learning from human feedback (RLHF) are vulnerable to reward hacking: as the policy maximizes a learned proxy reward, true quality plateaus or degrades. We make the assumption that reward hacking is often caused by flipped advantage signs: instead of reducing the likelihood of a bad response, a flipped sign causes the update to increase it. By considering an adversarial perturbation in the RM parameter space, we can derive a certified sign-preservation radius, which is the smallest perturbation that can flip the advantage sign during policy optimization. Based on this formulation, we propose Sign-Certified Policy Optimization (SignCert-PO), down-weighting non-robust completions in the policy gradient update. Unlike prior approaches that require multiple RMs or access to the RM training data, SignCert-PO is lightweight and operates purely at the policy optimization stage using only the RM parameters and on-policy completions. On TL;DR summarization and AlpacaFarm benchmarks, SignCert-PO consistently achieves a better win rate than baselines and reduces reward hacking.